Text(verarbeitung) in Processing.py
Mit print() oder println() kann man in Processing.py jede Ausgabe in das Konsolenfenster bringen, aber was ist, wenn der Text im Graphikfenster ausgegeben werden soll? Ich gehe erst einmal ganz naiv ran:
font = None
tt = "Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich."
def setup():
size(800, 100)
font = createFont("American Typewriter", 20)
textFont(font)
def draw():
background(255)
fill(0)
text(tt, 25, 50)
In der ersten Zeile teile ich Processing.py mit, daß ich die Variable font verwenden will und belege sie mit dem Wert none. Das erspart mir ein oder sogar zwei Global-Statements. Die Stringvariable tt bekommt meinen Text zugewiesen. In setup() mache ich ein langes, schamles Fenster auf (mein Text ist ja ziemlich lang) und dann teile ich mit createFont() Processing.py mit, daß ich den Font American Typewriter in der Größe von 20 Pixeln verwenden will und weise ihn der Variablen font zu. Zu guter Letzt lege ich noch fest, daß eben mein textFont font ist.
In draw() lege ich einen weißen Hintergrund und eine schwarze Füllfarbe fest und lasse dann mit der Funktion text() den Text in das Fenster zeichnen. text() besitzt drei Parameter, zuerst den zu schreibenden (oder besser: zeichnenden) Text, dann die x- und die y-Koordinate des Textbeginns.
Das sieht eigentlich alles ganz einfach aus, aber wenn Sie den Sketch ausführen lassen, erleben Sie ein blaues Wunder:

So verstümmelt haben Sie sich das sicher nicht vorgestellt. Die Ursache ist einfach und ärgerlich. Das Processing.py zugrundeliegende Python ist ein Jython (also die Java-Version von Python) und entspricht der Python-Version 2.7. Diese ist leider nicht out of the box UTF-8 fähig, ein Umstand, der in der (meist englischsprachigen) Literatur geflissentlich verschwiegen wird1. Dabei ist er so leicht zu beheben. Ein vor einem String vorangestelltes u teilt Python 2.7 mit, daß dieser String ein UTF-8-String ist. Im Sketch ist also lediglich die Zeile
tt = "Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich."
in
tt = u"Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich."
und schon wird der Text wie gewünscht ausgegeben:

Es gibt eine weitere, kleine Ungereimtheit im Umgang mit UTF-8 in Processing.py Im Haupt-Tab, in dem das ausführbare Programm steht (das ist der Tab, der die Endung .pyde bekommt), kann man – wie gezeigt – ohne große Probleme im Programmtext Umlaute unterbringen, während der Code in den anderen Tabs (die unter .py gespeichert werden) strenger mit dem Programmierer umgeht: Wenn nicht in der ersten Zeile
# coding=utf-8
steht, meckert die IDE gnadenlos, selbst wenn Umlaute nur in den Kommentaren vorkommen.
Der Text mit den zwölf Boxern ist übrigens ein Pangramm, ein Satz, der alle Buchstaben des (in diesem Falle deutschen) Alphabets enthält. Früher wurden sie benutzt, um zum Beispiel Schreibmaschinen nach einer Reparatur auf korrekte Funktion zu testen. Heute nutze ich ihn, um festzustellen, ob ein Font auch alle Umlaute des deutschen Alphabets enthält. Das bekannteste englische Pangramm ist der Satz »The quick brown fox jumps over the lazy dog«.
Als die Pangramme laufen lernten
Während in der Funktion text() die y-Koordinate immer die Grundlinie des Textes ist, kann man mit textAlign() festlegen, ob die x-Koordinate die rechte Kante (RIGHT), die linke Kante (LEFT) oder die Mitte (CENTER) des Textes betrifft. Das möchte ich ausnutzen, um eine Parade der Pangramme zu programmieren. Als erstes lege ich eine Liste mit Pangrammen an (der oben verlinkte Wikipedia-Artikel ist voll von ihnen). Und damit es auch ein wenig bunt wird, habe ich eine gleichlange Liste mit Farben zusammengestellt. Im Endeffekt soll das dann so aussehen:

Der Sketch selber ist dadurch ein wenig länger geworden, aber das betrifft in der Hauptsache nur die beiden Listen:
font = None
pangramme =
[u"Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich.",
u"Jörg bäckt quasi zwei Haxenfüße vom Wildpony.",
u"Falsches Üben von Xylophonmusik quält jeden größeren Zwerg.",
u"Schweißgequält zündet Typograph Jakob verflixt öde Pangramme an.",
u"Vom Ödipuskomplex maßlos gequält, übt Wilfried zyklisches Jodeln.",
u"Asynchrone Bassklänge vom Jazzquintett sind nix für spießige Löwen."]
colors = ["#cd0000", "#008b00", "#ffff00", "#a52a2a", "#ff00ff", "#00ffff"]
def setup():
global x, index
frame.setTitle("Parade der Pangramme")
size(800, 100)
font = createFont("American Typewriter", 24)
textFont(font)
x = width
index = 0
def draw():
global x, index
background(0)
fill(colors[index])
textAlign(LEFT)
text(pangramme[index], x, 60)
x -= 3
w = textWidth(pangramme[index])
if (x < -w):
x = width
index = (index+1) % len(pangramme)
Mit textAlign(LEFT) und x = width habe ich festgelegt, daß der Text im ersten Schritt am rechten Fensterrand beginnt und quasi ins Leere geschrieben wird. Bei jedem Durchlauf wird x umd drei dekrementiert und so beginnt das erste Pangramm von rechts nach links durch das Fenster zu scrollen. Ist der Text aus dem sichtbaren Bereich des Fenster verschwunden (x < -w), dann wird index um einen erhöht und das nächste Pangramm beginnt seine Parade. Damit der Index nicht irgendwann überläuft wird er Modulo der Länge der Liste der Pangramme berechnet. Und da ich in weiser Voraussicht die Länge der Farbliste gleich der Länge der Liste der Pangramme entworfen habe, passiert auch bei den Farben nichts.
Font, Font, Font
Jetzt bleibt nur noch eins zu tun. Auf meinem Rechner läuft der Sketch ohne Probleme, da ich weiß, daß auf meinen Rechner der Font American Typewriter vorhanden ist. Dies muß aber nicht auf jedem anderen Rechner der Fall sein (falls also bei Ihnen die Sketche nicht laufen, tauschen Sie einfach American Typewriter mit einem anderen Font, der auf Ihrem Rechner vorhanden ist, aus). Wenn ich die .ttf-Datei des Fonts in den data-Ordner des Sketches kopiere (das geht am einfachsten, wenn ich die Datei auf das Editor-Fenster der IDE schiebe), würde der Sketch – wenn ich ihn weitergebe – überall funktionieren. Aber American Typewriter unterliegt mit Sicherheit dem Urheberrecht und eine Weitergabe ist vermutlich verboten oder mit hohen Kosten verbunden.
Aber es gibt ja eine Menge freier Fonts im Web und die größte Quelle dieser freien Fonts ist Google Fonts. Dort habe ich mir den Font Barrio heruntergeladen, der unter der Open Font Licence zu nutzen ist.

Selbstverständlich habe ich mich vorher vergewissert, daß der Font auch die von mir gewünschten deutschen Umlaute enthält. Nachdem ich die Fontdatei dem Sketch hinzugefügt hatte, war eigentlich nur noch eine Zeile im Programm zu ändern:
font = createFont("Barrio-Regular.ttf", 64)
Barrio ist ein Display-Font, der nur ab einer gewissen Größe wirkt. Daher habe ich ihn auf 64 gesetzt und dann die y-Koordinate etwas weiter nach unten geschoben. Der vollständige und endgültige Sketch der Pangramm-Parade sieht daher nun so aus:
font = None
pangramme =
[u"Zwölf Boxkämpfer jagen Eva quer über den großen Sylter Deich.",
u"Jörg bäckt quasi zwei Haxenfüße vom Wildpony.",
u"Falsches Üben von Xylophonmusik quält jeden größeren Zwerg.",
u"Schweißgequält zündet Typograph Jakob verflixt öde Pangramme an.",
u"Vom Ödipuskomplex maßlos gequält, übt Wilfried zyklisches Jodeln.",
u"Asynchrone Bassklänge vom Jazzquintett sind nix für spießige Löwen."]
colors = ["#cd0000", "#008b00", "#ffff00", "#a52a2a", "#ff00ff", "#00ffff"]
def setup():
global x, index
frame.setTitle("Parade der Pangramme")
size(800, 100)
font = createFont("Barrio-Regular.ttf", 64)
textFont(font)
x = width
index = 0
def draw():
global x, index
background(0)
fill(colors[index])
textAlign(LEFT)
text(pangramme[index], x, 80)
x -= 3
w = textWidth(pangramme[index])
if (x < -w):
x = width
index = (index+1) % len(pangramme)
Wenn Sie noch mehr über Strings, Text und Fonts in Processing.py wissen wollen, Daniel Shiffman hat dazu ein nettes Tutorial verfaßt, daß auch mir bei meinen Erkundungen sehr geholfen hat.
UTF-8-Text aus Dateien lesen
In der Reference für Processing 3 steht bei allen Datei-Operationen, so auch bei loadStrings():
Starting with Processing release 0134, all files loaded and saved by the Processing API use UTF-8 encoding. In previous releases, the default encoding for your platform was used, which causes problems when files are moved to other platforms.
Das ließ hoffen, daß man in Processing.py wenigstens an dieser Stelle ohne das (von mir) ungeliebte u"utf-8-string" auskommen kann. Das wollte ich ausprobieren, also legte ich mir als erstes eine (UTF-8-) Textdatei mit diesem Inhalt an:
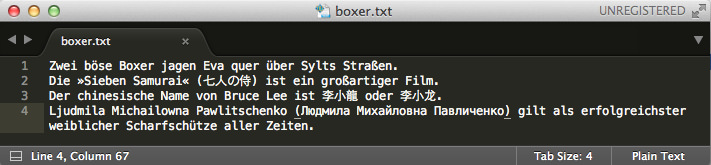
Das sieht doch schon sehr gefährlich aus, in der ersten Zeile die bösen deutschen Umlaute, die zweite Zeile mit japanischen Schriftzeichen, die dritte enthält chinesische Glyphen und die letzte Zeile kyrillische (russische) Zeichen. Noch vor wenigen Jahren hätte das jeden Programmierer an den Rand des Wahnsinns gebracht, aber nun: Selbst dieser simple Dreizeiler
lines = loadStrings("boxer.txt")
for line in lines:
print(line)
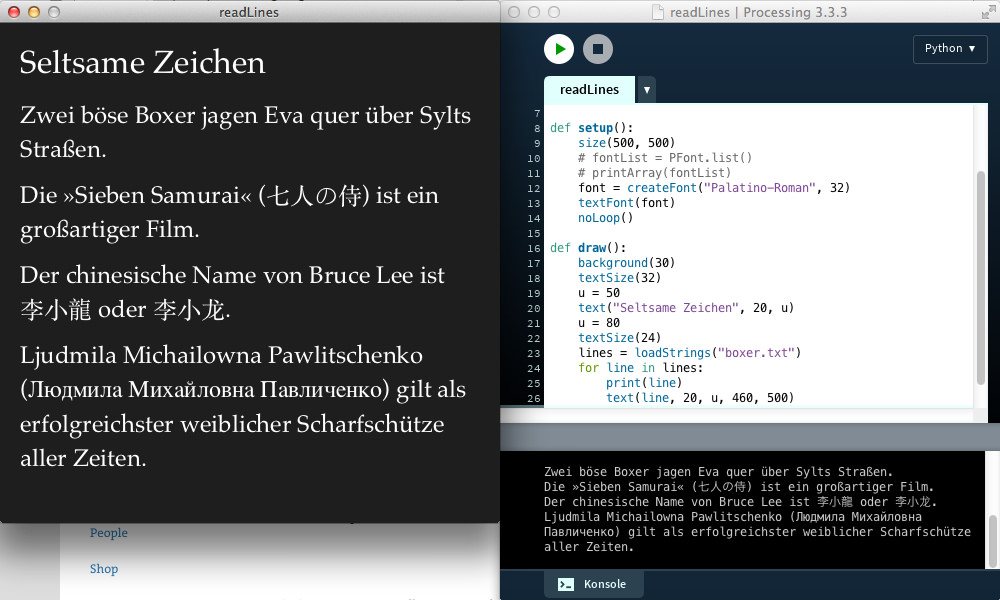
gibt den Text mit allen Sonderzeichen auf der Konsole aus. Und auch der Befehl text(line, x, y, w, h) hat keine Schwierigkeiten (einen UTF-8-fähigen Font vorausgesetzt) diesen Text in das Processing-Fenster zu zaubern. Hier das Progrämmchen, das obigen Screenshot produziert:
font = None
def setup():
size(500, 500)
# fontList = PFont.list()
# printArray(fontList)
font = createFont("Palatino-Roman", 32)
textFont(font)
noLoop()
def draw():
background(30)
textSize(32)
u = 50
text("Seltsame Zeichen", 20, u)
u = 80
textSize(24)
lines = loadStrings("boxer.txt")
for line in lines:
print(line)
text(line, 20, u, 460, 500)
u += 80
Die beiden auskommentierten Zeilen listen in der Konsole alle auf dem System verfügbaren Fonts auf, mit dem Namen, in dem sie mit createFont() in Processing angesprochen werden können. Wenn man einen dieser Fonts verwendet, erspart das zwar einerseits die Installation eines Fonts im data-Ordner, macht aber auf der anderen Seite solch ein Skript weniger portabel, denn was ist, wenn der Empfänger diesen Font nicht installiert hat.
Keine Emojis
In einer ersten Version des Textes hatte ich auch noch ein paar Emojis hineingeschmuggelt. Hier wurde aber eine Grenze überschritten, Emojis wurden weder in der Konsole noch auf dem Canvas angezeigt (man kann sie auch nicht per Copy & Paste) in den Editor schmuggeln`. Das gilt aber auch für den Java-Mode von Processing, Emojis sind erst ab P5.js in der Welt von Processing vorgesehen.
Caveat
Auch wenn ich es natürlich schön finde, daß das ungeliebte u"utf-8-string" bei den Dateioperationen mit Processing-Befehlen wegfällt, ist es natürlich inkonsistent. Denn Dateioperationen mit Python-Befehlen arbeiten natürlich weiterhin mit der besonderen UTF-8-Kodierung von Python 2.7, so zum Beispiel die Befehle um CSV- oder JSON-Dateien zu lesen und zu schreiben. Daher ist eine gewisse Vorsicht angebracht.
Spaß mit Processing.py: Rentenuhr
Was für Gründe sprechen eigentlich dafür, Processing.py statt des »normalen« Processings zu nutzen? Nun, zum einen können es persönliche Gründe sein: Ich mag zum Beispiel keine Programmiersprachen, die Blöcke mit geschweiften Klammern ({}) trennen und vermeide sie, wo es nur geht. Zum anderen komme ich aus der Pascal-Ecke (Pascal und Algol 68 waren meine ersten Programmiersprachen überhaupt) und mag daher Programme, die so etwas sind wie »ausführbarer Pseudocode«. Aber der wichtigste Grund ist, Processing.py ist eben nicht nur Processing, sondern auch Python. Und Python kommt »batteries included«, es bringt eine große Anzahl von Standard-Bibliotheken mit, die man auch in Processing.py nutzen kann. Ich möchte das am Beispiel des Python-Moduls datetime einmal zeigen:
Als erstes habe ich den freien (Open Font Licence) Font Coda Heavy von Googles Seiten heruntergeladen, entpackt und ihn dem Skript zugänglich gemacht, indem ich die .ttf-Datei einfach auf das IDE-Fenster geschoben habe. Processing legt dann automatisch im Skriptordner ein data-Vertzeichnis an und kopiert die Datei – wie auch alle Bild- oder Audio-Datein dorthin. Die Skripte finden sie dann, zum Beispiel mit
font = createFont("Coda-Heavy.ttf", 96)
ohne eine spezielle Pfadangabe. Der zweite Parameter gibt die maximale Fontgröße vor. Am Anfang des Skriptes habe ich mit
import datetime as dt
das Python-Modul datetime aus der Standardbibliothek geladen und dann als erstes eine einfache Uhr gebastelt
myNow = dt.datetime.now()
myHour = str(myNow.hour)
myMinute = str(myNow.minute)
mySecond = str(myNow.second)
und dann die datetime-Objekte in Strings verwandelt. Im eigentlichen Programm habe ich sie sogar noch ein wenig aufgehübscht und den einstelligen Sekunden und Minute eine führende Null verpaßt. Das könnt Ihr weiter unten im kompletten Quellcode nachlesen.
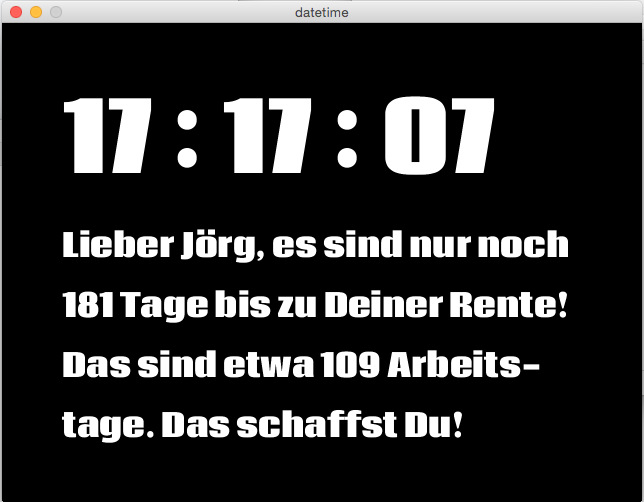
Jetzt kommt aber der eigentliche Gag: Mit den datetime-Objekten kann man nämlich rechnen! Und da ich am 31. Dezember 2018 in Rente gehe, wollte ich wissen, wieviele Tage ich noch ausharren muß
rente = dt.date(2018, 12, 31)
heute = dt.date.today()
differenz = rente - heute
myDays = str(differenz.days)
workingDays = float(myDays)/7.0 * 5
workingDays = str(int(workingDays - 15))
und wieviele Tage davon Arbeitstage sind. Dazu habe ich einfach die Anzahl der Tage durch sieben geteilt und mit fünf multipliziert, was grob die Anzahl der Werktage ergibt. Und da ich noch einige Tage Resturlaub in dieses Jahr mitgeschleppt habe, habe ich diese 15 Tage auch noch abgezogen. Die Feiertage habe ich nicht berücksichtigt, mir reicht diese grobe Schätzung.
Da die Differenz zweier datetime-Objekte wieder ein datetime-Objekt ist, muß die Umwandlung in einen String explizit mittels Typecasting vorgenommen werden und bei der Division durch sieben ist zu beachten, daß das Processing.py zugrundelegende Jython ein Python 2.7 ist und deshalb bei einer Integer-Division alle Nachkommastellen abschneidet (zum Beispiel ergibt 13/7 eine 1, dieses – dokumentierte – Verhalten wurde in Python 3 geändert). Um das zu vermeiden, habe ich durch 7.0 geteilt und so eine Float-Division erzwungen und durch ein anschließendes Runden das Ergebnis doch wieder in eine Integer-Zahl verwandelt.
Jetzt das komplette Skript zum Nachlesen und Nachprogrammieren:
import datetime as dt
def setup():
size(640, 480)
font = createFont("Coda-Heavy.ttf", 96)
textFont(font)
def draw():
background("#000000")
myNow = dt.datetime.now()
myHour = str(myNow.hour)
myMinute = str(myNow.minute).rjust(2, "0")
mySecond = str(myNow.second).rjust(2, "0")
myTime = myHour + " : " + myMinute + " : " + mySecond
textSize(96)
text(myTime, 60, 150)
rente = dt.date(2018, 12, 31)
heute = dt.date.today()
differenz = rente - heute
myDays = str(differenz.days)
workingDays = float(myDays)/7.0 * 5
workingDays = str(int(workingDays - 15))
myText = u"Lieber Jörg, es sind nur noch " + myDays + \
u" Tage bis zu Deiner Rente!\nDas sind etwa " + \
workingDays + " Arbeits- tage. Das schaffst Du!"
textSize(32)
text(myText, 60, 200, 540, 300)
Wegen des Umlautes in meinem Vornamen, mußte ich mit u"…" die Umwandlung des Strings in einen UTF-8-String erzwingen (auch das ist Python 3 nicht mehr nötig), aber wie der obige Screenshot zeigt, wird dann der Umlaut auch brav angezeigt.
Die Funktion text() kann man in Processing einmal mit drei und einmal mit fünf Parametern aufrufen. Im ersten Fall übergibt man den Text und die x- und y-Koordinaten der linken Grundlinie des Textes. Im zweiten Fall kommen noch die Weite und die Höhe der Textbox hinzu. Damit erreicht man, daß ein langer String an den Textbox-Grenzen umgebrochen wird und der Text nicht aus dem Fenster herausläuft. Die Parameter habe ich durch einfaches Ausprobieren bekommen.
-
Ich weiß nicht, ob je und wann Jython den Sprung auf Python 3 wagt. Dort ist jedenfalls von Hause aus (per Default) jeder String ein UTF-8-String, in meinen Augen ein wichtiger, aber auch der einzige Grund, auf Python 3 umzusteigen. ↩